在本章节中,作者要介绍的是断句算法。断句算法的主要目的,就是将输入数据库的段落语料,切分成合理的完整的句子。整个处理过程需要保持句子的相对完整性。如下图所示:
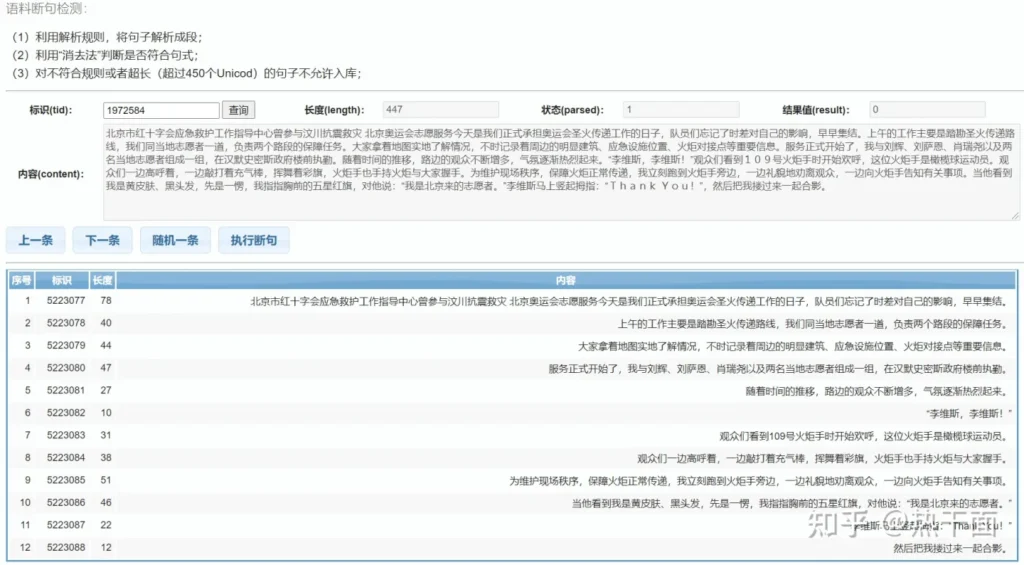
上面的例子中,将一条新闻报道切分成若干完整的单句。切分后的单句再供给后续的算法做进一步分析。
算法的实现
断句算法的实现,读者可以用正则算法模块去实现,这里就不再做赘述。只是正则模块需要预备比较多的模板,这个工作量也不轻松。
这里要介绍的是作者自己描述的一种算法过程。这个过程总体上也可以归为正则算法的一种变种。
1 标点符号
首先就是要确定断句算法的相关标点符号。哪些符号被认为是断句的主要标志。
实际应用中,关于标点符号会碰到如下问题:
- 标点符号因为中文和英文而有所不同,是有全角和半角字符之分。
- 有些中文标点和英文标点之间有对应关系(例如:句号),有些则没有(例如:中文有正反两种引号,英文只有一种引号)。
- SQLServer缺省字符集下不分全角半角。
- 语料中随时可能碰到的不可见字符和空格。在不清楚语义之前,对这些字符的删除或者清理,是会导致后续分析上的错误。
- 语料的标点符号使用的规范性等因素。标点符号的使用不符合规范,会导致正则模块和断句算法产生错误。一般情况下,可以人工大致看一下,不符合规范的语料直接抛弃即可。
作者所描述的算法对标点符号做了如下规范:
- 主要的标点符号包括:句号(。)、逗号(,)、分号(;)、冒号(:)、问号(?)和感叹号(!)。
- 配对的标点符号包括:双引号(“”)、单引号(‘’)、小括号(())、书名号(《》)、中括号(【】)和尖括号(〈〉)。
- 其他未在规范内的符号,均作为普通字符看待。这些符号包括:顿号(、)、省略号(…)、破折号(—)、空格、英文单引号、英文双引号等等。
断句作为语料的预处理过程,不用特别细致,关键是把句子与句子之间分开即可。剩余的符号,可以交予后续的算法进一步分析。
没有选择英文单引号和英文双引号作为断句的标点符号,主要原因是这两种符号没有正反向。一旦因为语料残缺或者导入出错,那么引号内的内容就完全反向了(即原来引号内的内容,成了外部内容;而外部内容成了内部内容)。
这里需要指出的是,在数量描述中有一种方式会和句子描述的方式有重叠的地方会对断句有稍许影响。例如:……价值2, 300美元……。这里的这种分段数字表达方式,使用到了逗号,对断句会有一定的干扰。这个可以通过提前通过正则方法提取数量词来解决。这样的情况在实际分析时会遇到一些。总体上来说,仍是比较少见。
2 字符串
不含(1)中所定义的标点符号的文本定义为字符串。
由定义可知,在字符串中,仍可能存在一些其他符号,只是这些符号暂时不影响断句算法。
3 规则描述
规定用“$”符号表示字符串。用a~z标识字符串a至字符串z。一个单句允许最多定义26个字符串。另外,考虑到SQLServer索引的限制,因此一个单句的最大长度定义在450个Unicode。
如:$a。表明规则就一个字符串,以句号结尾。例如:“这是黑色的。”这个例子就符合该规则。“这是黑色的,我不太喜欢。”这例子就不符合该规则,但是符合规则$a,$b。
给一个稍微复杂的规则,读者可以自行分析:$a:“$b:‘$c!’$d。”
为了加快匹配速度和效率,还特别定义了一个规则的缩写模式:将规则描述中的a~z去掉后的描述。例如:$a:“$b:‘$c!’$d。”的缩写形式就是:$:“$:‘$!’$。”
4 消减规则
从上面的规定可以看出,如果能把所有符合单句的规则都写出来,那么就可以直接按照模板套用。实际上,很难做到这一点,主要原因有两个:
- 单句的模式种类很多,如果枚举规则,将无穷无尽。
- 即使可以枚举大多数,数据库中记录的规则也非常多,每个规则都去尝试,将会严重降低算法的效率。作者曾经利用断句算法将语料中的句子形态部分抽取出来,总计大约3万多种。如果逐一匹配,处理效率很低。
为了把一个陌生的单句规则,逐步转化成熟悉的单句规则,特别定义了一个消减规则。下面举几个例子说明:
- 规则(1)拼接规则:$a$b可以化简为规则$a。
- 规则(2)配对规则:“$a”、‘$a’、($a)、《$a》、【$a】、〈$a〉可以化简为$a。
- 规则(3)缩减规则:$a,$b、$a:$b可以化简为规则$a。
- 规则(4)复句规则:$a。$b、$a?$b、$a!$b可以化简为规则$a。
- 规则(5)单句规则:$a。、$a,“$b;$c,”$d。
5 处理过程
5.1 分解语料
分解语料的过程比较简单:
- 从语料起始部分开始扫描。
- 如果遇到的是标点符号,则生成一个子字符串。每个子字符串仅含一个标点符号。
- 如果遇到的是非标点符号,则向后连续提取字符,直至遇到标点符号为止。为了区别这类字符串与标点符号字符串的区别,特别在字符串前面增加了一个美元符号(“$”)。
分解语料的过程十分简单,这里不再贴程序。后面会用实例加以说明。
5.2 合并分段
将分解后所获得的子字符串进行适当合并,简化句子,直至最简模式。
合并包含三个部分:合并引用,合并分段,合并复合句。
(1)合并引用
合并引用主要是用于合并引号、书名号、括号之内的内容,将这些内容连同标点符号“化成”一个简单字符串。
(2)合并分段
如果相邻的两个子字符串都是非标点的普通内容,则将两个字符串“化成”一个简单字符串。
(3)合并复句
如果相邻的两个子字符串都是简单的句子。则将两个字符串“化成”一个简单字符串。
合并还有其他一些细节上的要求(例如:双引号对合并的影响),这样可以较为精细地控制句子的合并过程。这里只大致讲一下过程。最后还是要看实例,才能更好理解。
5.3 模板匹配
当“化简”到无法再继续合并时,就可以使用句子模板进行匹配。能匹配成功的部分,就提取出来形成完整的句子。经过最终挑选,其实所使用的模板并不是很多:
public class SentenceExtractor
{
// 句式模板
// 不要调整顺序!!!
private static readonly string[][] TEMPLATES =
{
// 符号嵌套
new string[] {"“$", "$a", "(,|:|。|;|?|!)+‘$", "$b", "(。|;|?|!)*’$", "$c", "(。|?|!|…)+”$"},
new string[] {"“$", "$a", "(,|:|。|;|?|!|…)*”$", "$b", "(,|:)?“$", "$c", "(。|?|!|…)+”$"},
new string[] {"‘$", "$a", "(,|:|。|;|?|!|…)*’$", "$b", "(,|:)?‘$", "$c", "(。|?|!|…)+’$"},
new string[] {"「$", "$a", "(,|:|。|;|?|!|…)*」$", "$b", "(,|:)?“$", "$c", "(。|?|!|…)+”$"},
new string[] {"『$", "$a", "(,|:|。|;|?|!|…)*』$", "$b", "(,|:)?‘$", "$c", "(。|?|!|…)+’$"},
new string[] {"〝$", "$a", "(,|:|。|;|?|!|…)*〞$", "$b", "(,|:)?“$", "$c", "(。|?|!|…)+”$"},
new string[] {"【$", "$a", "(,|:|。|;|?|!|…)*】$", "$b", "(,|:)?‘$", "$c", "(。|?|!|…)+’$"},
new string[] {"$a", "(,|:)?“$", "$b", "(,|;|…)*”$", "$c", "(。|?|!|…)+$"},
new string[] {"$a", "(,|:)?‘$", "$b", "(,|;|…)*’$", "$c", "(。|?|!|…)+$"},
new string[] {"$a", "(,|:)?「$", "$b", "(,|;|…)*」$", "$c", "(。|?|!|…)+$"},
new string[] {"$a", "(,|:)?『$", "$b", "(,|;|…)*』$", "$c", "(。|?|!|…)+$"},
new string[] {"$a", "(,|:)?〝$", "$b", "(,|;|…)*〞$", "$c", "(。|?|!|…)+$"},
new string[] {"$a", "(,|:)?【$", "$b", "(,|;|…)*】$", "$c", "(。|?|!|…)+$"},
new string[] {"“$", "$a", "(,|:|。|;|?|!)+‘$", "$b", "(。|;|?|!|…)*’”$"},
new string[] {"“‘$", "$a", "(,|:|。|;|?|!|…)*’$", "$b", "(。|;|?|!|…)+”$"},
new string[] {"“$", "$a", "(,|:|。|;|?|!|…)*”$", "$b", "(。|?|!|…)+$"},
new string[] {"‘$", "$a", "(,|:|。|;|?|!|…)*’$", "$b", "(。|?|!|…)+$"},
new string[] {"$a", "(,|:)?“$", "$b", "(。|?|!|…)?”$"},
new string[] {"$a", "(,|:)?‘$", "$b", "(。|?|!|…)?’$"},
new string[] {"$a", "(,|:)?「$", "$b", "(。|?|!|…)?」$"},
new string[] {"$a", "(,|:)?『$", "$b", "(。|?|!|…)?』$"},
new string[] {"$a", "(,|:)?〝$", "$b", "(。|?|!|…)?〞$"},
new string[] {"$a", "(,|:)?【$", "$b", "(。|?|!|…)?】$"},
// 常见符号
new string[] {"$a", "(:)$", "$b", "(。|;|?|!|…)+$"},
new string[] {"$a", "(,|:)?“$", "$b", "(。|;|?|!|…)*”$"},
new string[] {"$a", "(,|:)?‘$", "$b", "(。|;|?|!|…)*’$"},
new string[] {"$a", "(,|:)?($", "$b", "(。|;|?|!|…)*)$"},
new string[] {"$a", "(,|:)?「$", "$b", "(。|;|?|!|…)*」$"},
new string[] {"$a", "(,|:)?『$", "$b", "(。|;|?|!|…)*』$"},
new string[] {"$a", "(,|:)?〝$", "$b", "(。|;|?|!|…)*〞$"},
new string[] {"$a", "(,|:)?《$", "$b", "》(。|?|!|…)+$"},
new string[] {"$a", "(,|:)?【$", "$b", "】(。|?|!|…)+$"},
// 符号嵌套
new string[] {"“‘$", "$a", "(,|:|。|;|?|!|…)*’”$"},
new string[] {"“($", "$a", "(,|:|。|;|?|!|…)*)”$"},
// 常见符号
new string[] {"“$", "$a", "(,|:|。|;|?|!|…)*”$"},
new string[] {"‘$", "$a", "(,|:|。|;|?|!|…)*’$"},
new string[] {"($", "$a", "(,|:|。|;|?|!|…)*)$"},
new string[] {"《$", "$a", "(,|:|。|;|?|!|…)*》$"},
new string[] {"【$", "$a", "(,|:|。|;|?|!|…)*】$"},
// 比较少见
new string[] {"「$", "$a", "(,|:|。|;|?|!|…)*」$"},
new string[] {"『$", "$a", "(,|:|。|;|?|!|…)*』$"},
new string[] {"〖$", "$a", "(,|:|。|;|?|!|…)*〗$"},
new string[] {"〝$", "$a", "(,|:|。|;|?|!|…)*〞$"},
// 最简单的句子
new string[] {"$a", "(。|;|?|!|…)+$"},
};
实例讲解
实例过程如下:
----------------------------------------
打印原始内容!
----------------------------------------
"我再说一遍,尊贵的太太,"我坚持道,"遇着这类事我既不愿审问,也不愿判决。在您面前,我可以平心静气地承认,我先前的话有 点过甚其词,--这位可怜的亨丽哀太太自然算不上女中豪杰,既不是天生的浪漫人物,更不是什么"伟大的情人"。她在我的眼里,据我所见到的,只不过是一个平庸而又软弱的女人,我对她多少怀着敬意,那是因为她勇敢地随顺了自己的意愿,可是我对她怀着更多的怜悯,因为她明天,如果不是在今天,一定会深深陷入不幸。她的举动也许很愚蠢,失于轻率,却决不能称为卑劣下流,我始终极力争辩的是:谁也没有权利鄙薄这个可怜的、不幸的女人。"
----------------------------------------
打印ClearContent后的内容!
----------------------------------------
"我再说一遍,尊贵的太太,"我坚持道,"遇着这类事我既不愿审问,也不愿判决。在您面前,我可以平心静气地承认,我先前的话有点 过甚其词,—这位可怜的亨丽哀太太自然算不上女中豪杰,既不是天生的浪漫人物,更不是什么"伟大的情人"。她在我的眼里,据我所见到的,只不过是一个平庸而又软弱的女人,我对她多少怀着敬意,那是因为她勇敢地随顺了自己的意愿,可是我对她怀着更多的怜悯,因为她明天,如果不是在今天,一定会深深陷入不幸。她的举动也许很愚蠢,失于轻率,却决不能称为卑劣下流,我始终极力争辩的是:谁也没有权利鄙薄这个可怜的、不幸的女人。"
----------------------------------------
打印SplitContent后的字符串内容!
----------------------------------------
$"我再说一遍
,
$尊贵的太太
,
$"我坚持道
,
$"遇着这类事我既不愿审问
,
$也不愿判决
。
$在您面前
,
$我可以平心静气地承认
,
$我先前的话有点过甚其词
,
$—这位可怜的亨丽哀太太自然算不上女中豪杰
,
$既不是天生的浪漫人物
,
$更不是什么"伟大的情人"
。
$她在我的眼里
,
$据我所见到的
,
$只不过是一个平庸而又软弱的女人
,
$我对她多少怀着敬意
,
$那是因为她勇敢地随顺了自己的意愿
,
$可是我对她怀着更多的怜悯
,
$因为她明天
,
$如果不是在今天
,
$一定会深深陷入不幸
。
$她的举动也许很愚蠢
,
$失于轻率
,
$却决不能称为卑劣下流
,
$我始终极力争辩的是
:
$谁也没有权利鄙薄这个可怜的、不幸的女人
。
$"
----------------------------------------
打印MergeContent后的字符串内容!
----------------------------------------
$"我再说一遍,尊贵的太太,"我坚持道,"遇着这类事我既不愿审问,也不愿判决
。
$在您面前,我可以平心静气地承认,我先前的话有点过甚其词,—这位可怜的亨丽哀太太自然算不上女中豪杰,既不是天生的浪漫人物 ,更不是什么"伟大的情人"
。
$她在我的眼里,据我所见到的,只不过是一个平庸而又软弱的女人,我对她多少怀着敬意,那是因为她勇敢地随顺了自己的意愿,可是 我对她怀着更多的怜悯,因为她明天,如果不是在今天,一定会深深陷入不幸
。
$她的举动也许很愚蠢,失于轻率,却决不能称为卑劣下流,我始终极力争辩的是:谁也没有权利鄙薄这个可怜的、不幸的女人
。
$"
----------------------------------------
打印GetSentences最终可以匹配的句子内容!
----------------------------------------
"我再说一遍,尊贵的太太,"我坚持道,"遇着这类事我既不愿审问,也不愿判决。
----------------------------------------
在您面前,我可以平心静气地承认,我先前的话有点过甚其词,—这位可怜的亨丽哀太太自然算不上女中豪杰,既不是天生的浪漫人物,更不是什么"伟大的情人"。
----------------------------------------
她在我的眼里,据我所见到的,只不过是一个平庸而又软弱的女人,我对她多少怀着敬意,那是因为她勇敢地随顺了自己的意愿,可是我对她怀着更多的怜悯,因为她明天,如果不是在今天,一定会深深陷入不幸。
----------------------------------------
她的举动也许很愚蠢,失于轻率,却决不能称为卑劣下流,我始终极力争辩的是:谁也没有权利鄙薄这个可怜的、不幸的女人。
----------------------------------------
这个实例中有一点意外,就是出现了双引号嵌套:“遇着这类事……“伟大的情人”……不幸的女人。“
这种标点嵌套(包括错用标点符号),是断句算法中最麻烦的部分。一般情况下,只要标点符号稍微出点错,就会对最终结果产生很大影响。
(1)首先,程序将提取到了原始内容进行了过滤。这个过程,程序还会对某些标点符号错误尝试纠正。
(2)然后开始分解字符串内容:
$"我再说一遍
,
$尊贵的太太
,
$"我坚持道
,
$"遇着这类事我既不愿审问
,
$也不愿判决
。
$在您面前
,
$我可以平心静气地承认
,
$我先前的话有点过甚其词
,
$—这位可怜的亨丽哀太太自然算不上女中豪杰
,
$既不是天生的浪漫人物
,
…………………………
双引号此时能出现在普通句子的前面,一定是半角的双引号。程序会准确识别全角的双引号,对半角双引号仅视为普通字符。
因此,此例中的对话句式,等于被剥夺了双引号,成为了普通句子。随后按照普通句子进行分割。后面一对双引号没有出现问题,是因为其恰好遇到了句号(“。”),所以没被断成两个部分。
(3)随后的合并和拼接相对比较简单。但是切分出来的句子,已经与原文的句子相差甚远。主要还是因为半角双引号无法引导程序正确处理句子。
下面再看一例:
----------------------------------------
打印原始内容!
----------------------------------------
“还有比这更漂亮的画吗?”他欣喜地说。“我的宝宝、乔治安娜·达西小姐、两个正当青春年华的迷人的尤物,还没有提,”他稍停片刻便急急补充说,“那个让我成为最幸福的男人的女人了。婚姻,比斯利,婚姻。珈苔琳夫人真是屈尊降贵,把它强加给我;我只好学她的样,把它推荐给你。这是你在世上能做的最好的事。”
----------------------------------------
打印ClearContent后的内容!
----------------------------------------
“还有比这更漂亮的画吗?”他欣喜地说。“我的宝宝、乔治安娜·达西小姐、两个正当青春年华的迷人的尤物,还没有提,”他稍停片刻便急急补充说,“那个让我成为最幸福的男人的女人了。婚姻,比斯利,婚姻。珈苔琳夫人真是屈尊降贵,把它强加给我;我只好学她的样,把它推荐给你。这是你在世上能做的最好的事。”
----------------------------------------
打印SplitContent后的字符串内容!
----------------------------------------
“
$还有比这更漂亮的画吗
?”
$他欣喜地说
。
“
$我的宝宝、乔治安娜·达西小姐、两个正当青春年华的迷人的尤物
,
$还没有提
,”
$他稍停片刻便急急补充说
,“
$那个让我成为最幸福的男人的女人了
。
$婚姻
,
$比斯利
,
$婚姻
。
$珈苔琳夫人真是屈尊降贵
,
$把它强加给我
;
$我只好学她的样
,
$把它推荐给你
。
$这是你在世上能做的最好的事
。”
----------------------------------------
打印MergeContent后的字符串内容!
----------------------------------------
“
$还有比这更漂亮的画吗
?”
$他欣喜地说
。
“
$我的宝宝、乔治安娜·达西小姐、两个正当青春年华的迷人的尤物,还没有提
,”
$他稍停片刻便急急补充说
,“
$那个让我成为最幸福的男人的女人了。婚姻,比斯利,婚姻。珈苔琳夫人真是屈尊降贵,把它强加给我;我只好学她的样,把它推荐给 你。这是你在世上能做的最好的事
。”
----------------------------------------
打印GetSentences最终可以匹配的句子内容!
----------------------------------------
“还有比这更漂亮的画吗?”他欣喜地说。
----------------------------------------
“我的宝宝、乔治安娜·达西小姐、两个正当青春年华的迷人的尤物,还没有提,”他稍停片刻便急急补充说,“那个让我成为最幸福的男人的女人了。婚姻,比斯利,婚姻。珈苔琳夫人真是屈尊降贵,把它强加给我;我只好学她的样,把它推荐给你。这是你在世上能做的最好的事。”
----------------------------------------
这次的基本过程和上列相同。在标点符号的正确引导下,语料被切分成相对完成的两句。
总结
(1)断句算法核心思路就是:先彻底打散,再视情况合并与消去,最后匹配模板即可。
(2)用于匹配的模板并不需要很多,最后的匹配可以使用正则表达式进行协助处理,避免程序过于复杂。
(3)标点符号对断句算法影响很大。错误的标点符号,会导致句子被错误地断开,或者分配到一起。
由于标点符号有嵌套问题,因此用消去法要比直接使用正则表达式要来得简单。
编译原理中常用的两种分析方法就是:自顶向下和自底向上两种分析方法。在自顶向下实现比较困难的时候,可以先采用自底向上的分析方法。