本章将介绍将原始语料导入到SQLServer的基本方法。这个也是实施自然语言处理所需要进行的第一个基础步骤。
导入原始文本数据的方法有很多,但是仍然需要注意以下问题:
(1)编码方式
有的原始文本数据编码方式符合GB标准,有的则是Unicode,有的则是UTF8,有的则是繁体。在导入数据之前一定要用其他的编辑器查看以下,以确定原始文本数据的编码方式是否可以统一到某种利于导入的编码方式上。
(2)换行方式
有的原始文本使用正常的换行符换行,有的则是手工强制换行。手工强制换行的文本数据对原始文本数据会造成无意义的强行截断,不利于后期分析。遇到这种文本数据,应当主动放弃。毕竟可以找到的原始文本数据很多,没必要在这些数据上浪费时间。
还有一些原始文本数据,干脆没有任何换行,从头一直拖到尾。只要SQLServer单行数据能吃得下,就导入,否则就直接放弃。道理和上面所说的一致。
(3)无关字符过多的文本
有很多原始文本数据是从网页上拷贝下来的,因此会带有大量的HTML标记。这些标记会严重干扰分析,去除这些标记要费很多精力和时间。因此这种文本不适用。对于这种问题,最简单的办法就是:宁可花点小钱,去淘宝上买几个G的小说,也不要浪费时间在处理这种HTML标记上。
(4)经过整理的数据字典
网络上还有不少经人整理过的文本内容和字典。这些数据基本上比较规矩,易于导入。但是千万不要把这些数据奉为标准,只能当作较为正规的原始数据来对待。
SQLServer导入文本数据的方式有两种:
(1)Bulk批量插入
bulk insert [DatabaseName].[dbo].[table] from 'C:\data.txt'
with(
FIRSTROW =1, --指定要加载的第一行的行号。默认值是指定数据文件中的第一行
CODEPAGE=''936'', --数据库中的编码类型
FIELDTERMINATOR='','', --分隔符
ROWTERMINATOR='/n' --换行符
)
可以使用SQL语句实现文本的读入,并插入到临时表中。
(2)使用导入工具
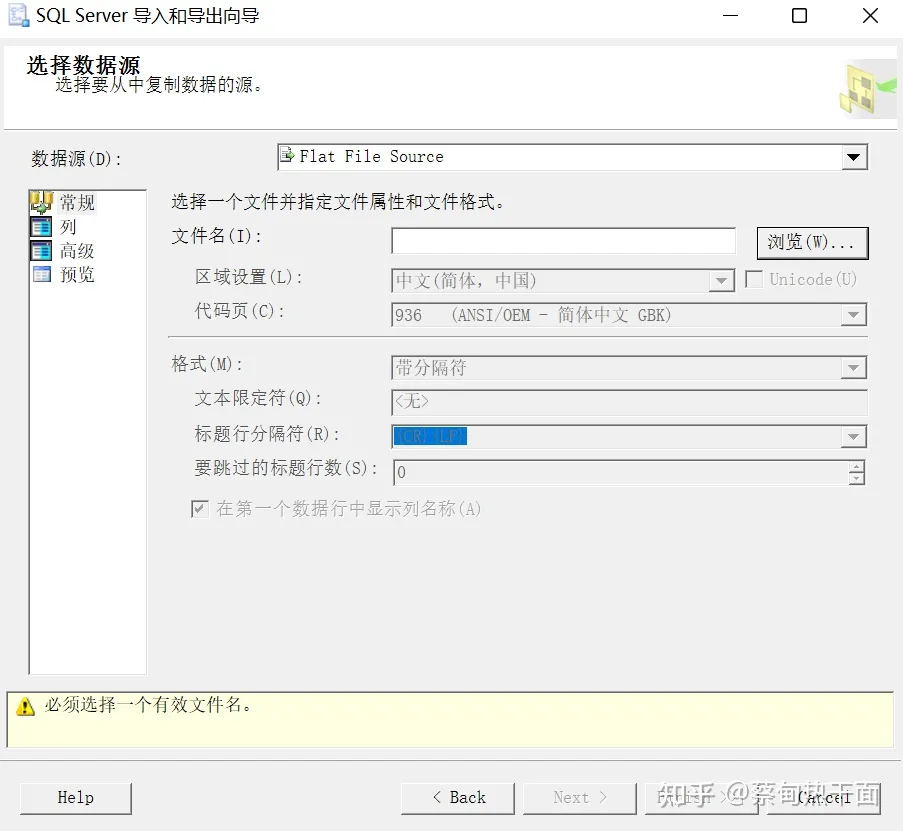
使用SQLServer文件导入工具,也可以将文本文件导入到临时表之中。使用该工具时注意以下几点:编码方式、列宽、分割符。选择好配置后,最好先预览以下。如果编码方式不对,则调整原始文本数据。如果列宽不够,则将列宽调整到最大数值,或者使用stream读入方式。这个部分的具体问题,需要读者自行摸索,这里不再做赘述。总的来说,导入工具比SQL语句方便,对于初次使用的人非常合适。
原始数据导入到临时表后,下一步就是要将临时数据表中的内容导入到正式语料表中。
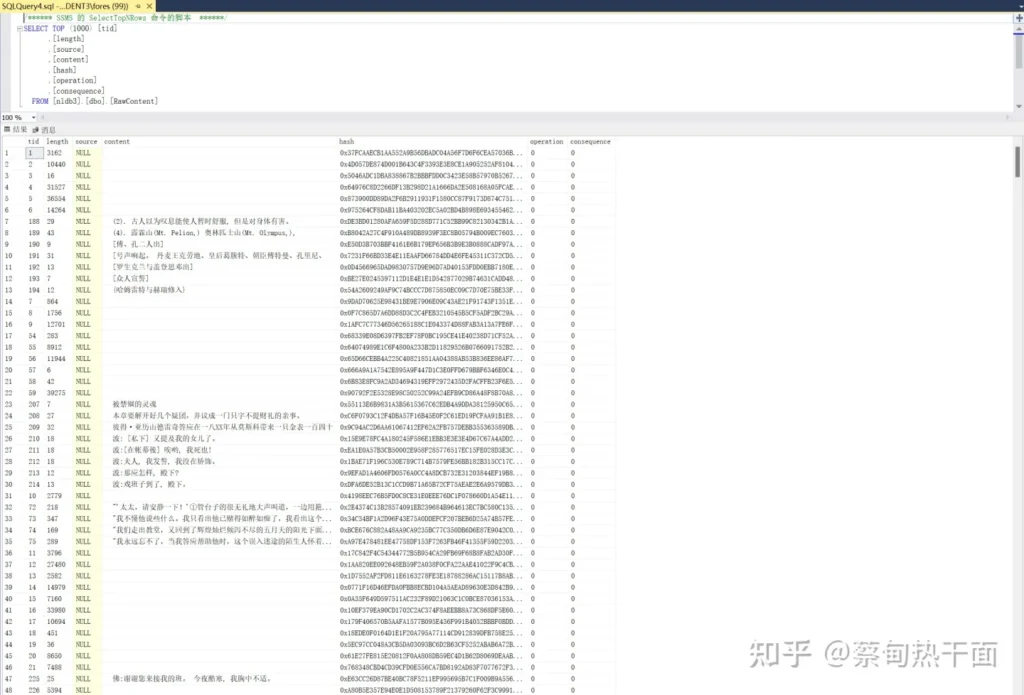
正式语料表中的content字段选择的是NVARCHAR(MAX),尽可能多的容纳文本数据。source表明的是文本的来源,即从哪个原始数据文件来的数据。hash字段是基于SHA2_512编码的补充字段,主要是为了防止语料的重复导入。
读者可能会注意到图中,有很多空白行,但是其length和hash都不一样。这样的行为什么不清理掉,还要留在正式语料库中。
空白行是因为有很多不可见的UNICODE字符,而且这些字符的数值并不一样。不清理这些数据的根本原因是想保留一份最原始(或者说最混乱)的数据。后面会有很多处理会对这些数据进行清洗。
但是无论如何清洗,这些原始数据不能改动。一方面是用于检测后续清洗过程的完备性和可靠性;另一方面,如果一旦清理原始数据出错,就会导致原始语料库乱掉,最后越改越乱。这样所有的前期工作就全作废了。
在NLDB库中,RawContent中的原始语料总计10,101,284条。字典部分的数据由单独的数据表存储,并不在此表之中。绝大多数的数据来源于网络小说。IP文的蓬勃发展给自然语言处理提供了丰富的语料来源。