Tire树是一种字典树,也是一种多叉树结构。

实际上按照本文所叙述的理论,Tire树可以归结为商数类哈希函数。其采用26位计数进制方式(以英文字母为基础)。
下面是有关于英文单词的统计情况:

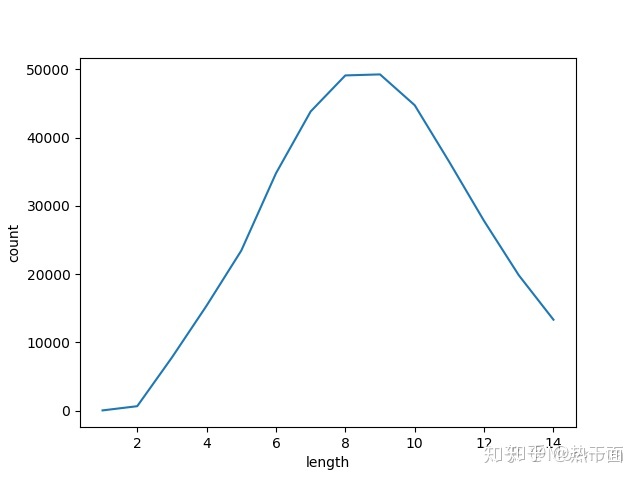

由以上数据统计可以分析得出Tire树的基本情况:
- 最大查找长度至少要设置至20。
- 平均最大查找长度应当接近于8。
- 各个分支路径上的数据记录分布不均匀,某些路径上过多,某些路径上过少。
如果使用哈希树进行处理,则可以做到如下几点:
- 无需对英文单词的长度做出限制。
只是单词较长时,取余运算需要消耗较多CPU时间。也可以对英文单词预先使用余数类哈希函数进行处理,将结果数值作为字符串的关键字。这样处理整数要远优于处理长字符串。 - 目前英文单词数量超过100万,常用单词5万。以本文推荐的除数数列\(M^*\)为例,那么最大查找长度预估为3(256×255×253 = 16515840,远大于1000000),其平均查找长度应该不超过3。
- 数据记录都会靠近根节点,各分支路径数据是均衡的。可以通过优先插入出现频次高的单词,再插入出现频次低的单词,提高查询击中概率,减少平均查找长度。
以上就是哈希树在处理英文单词时相对于Tire树的优势。